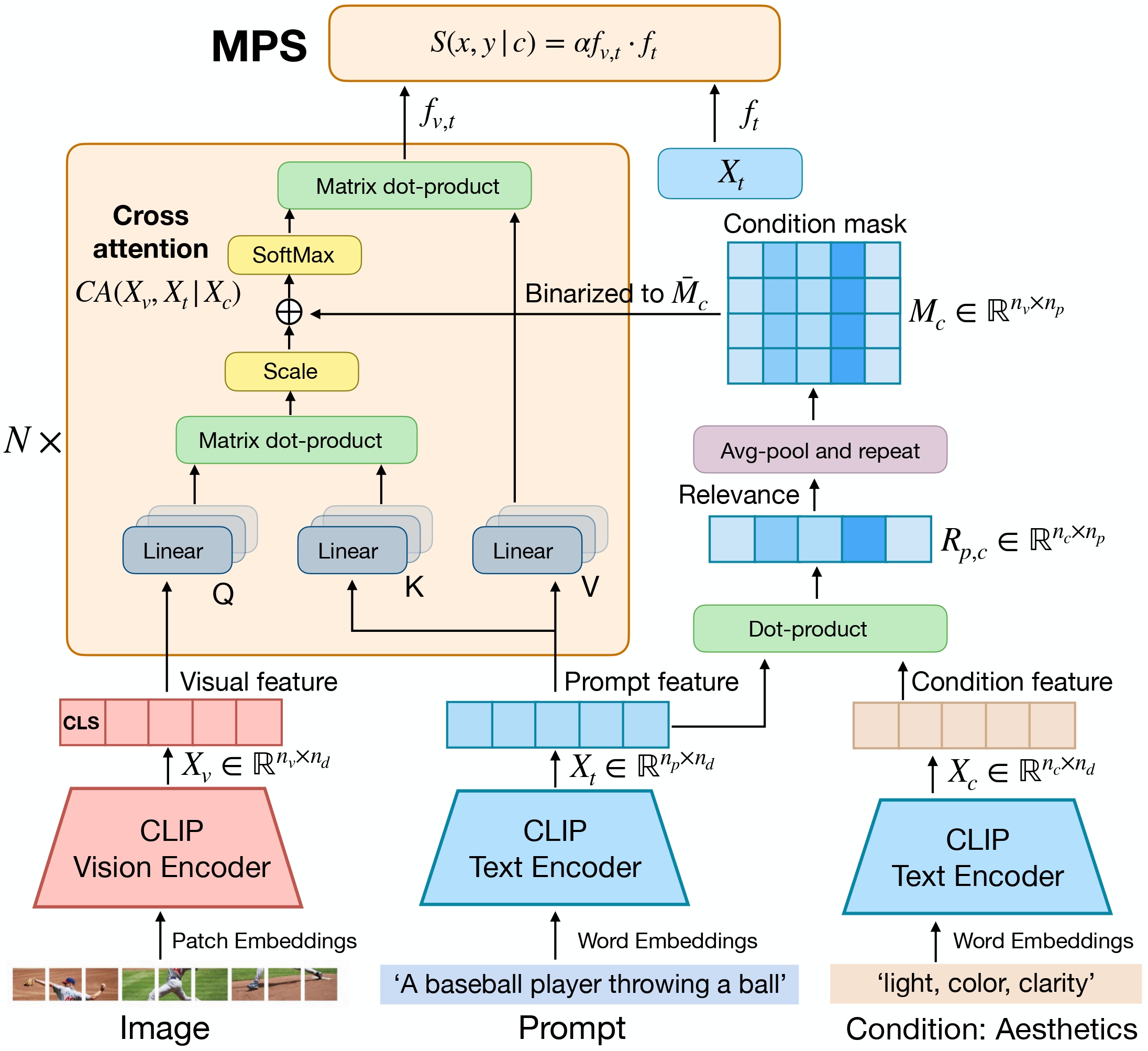
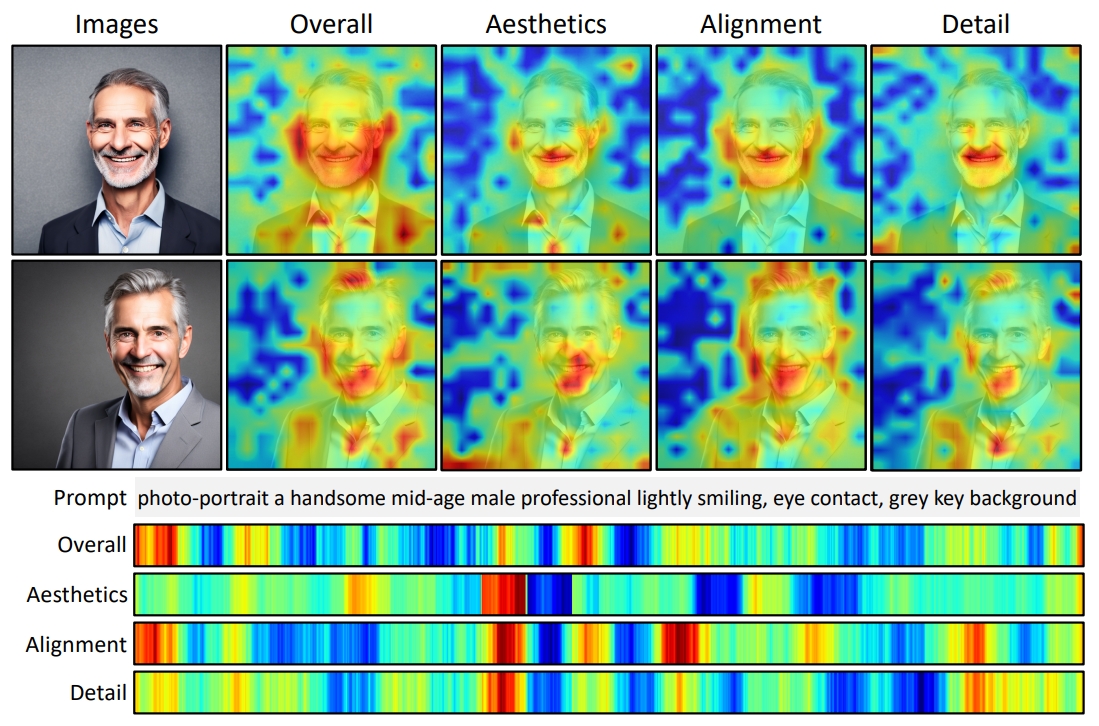
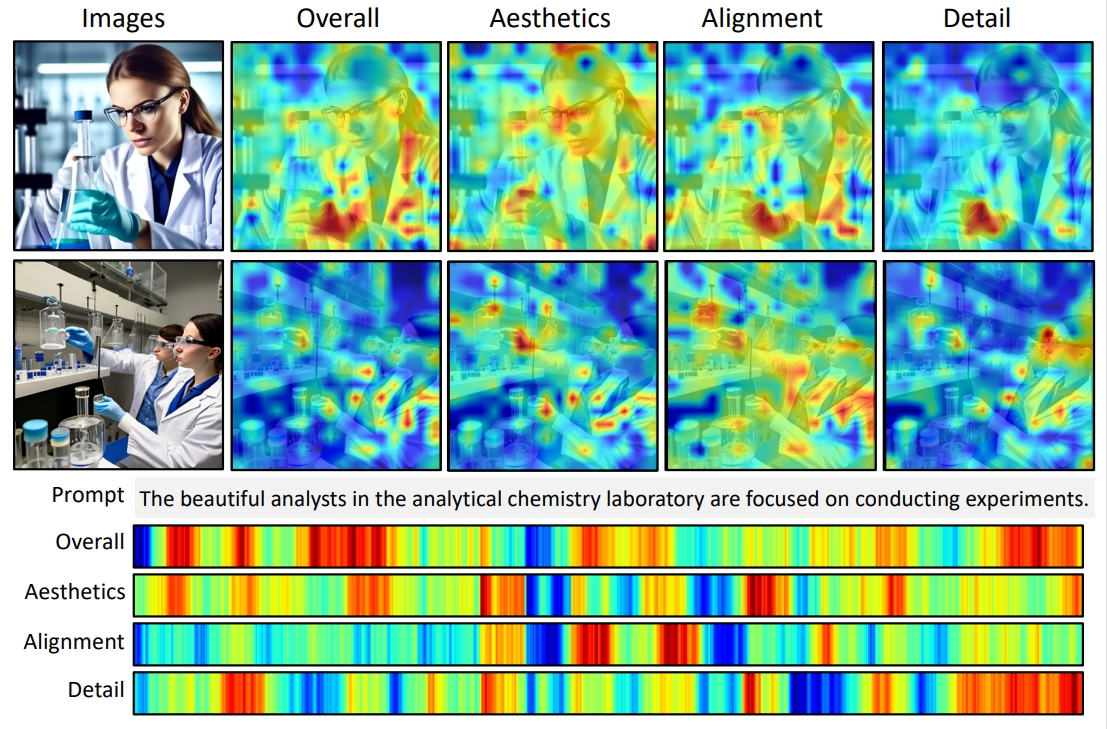
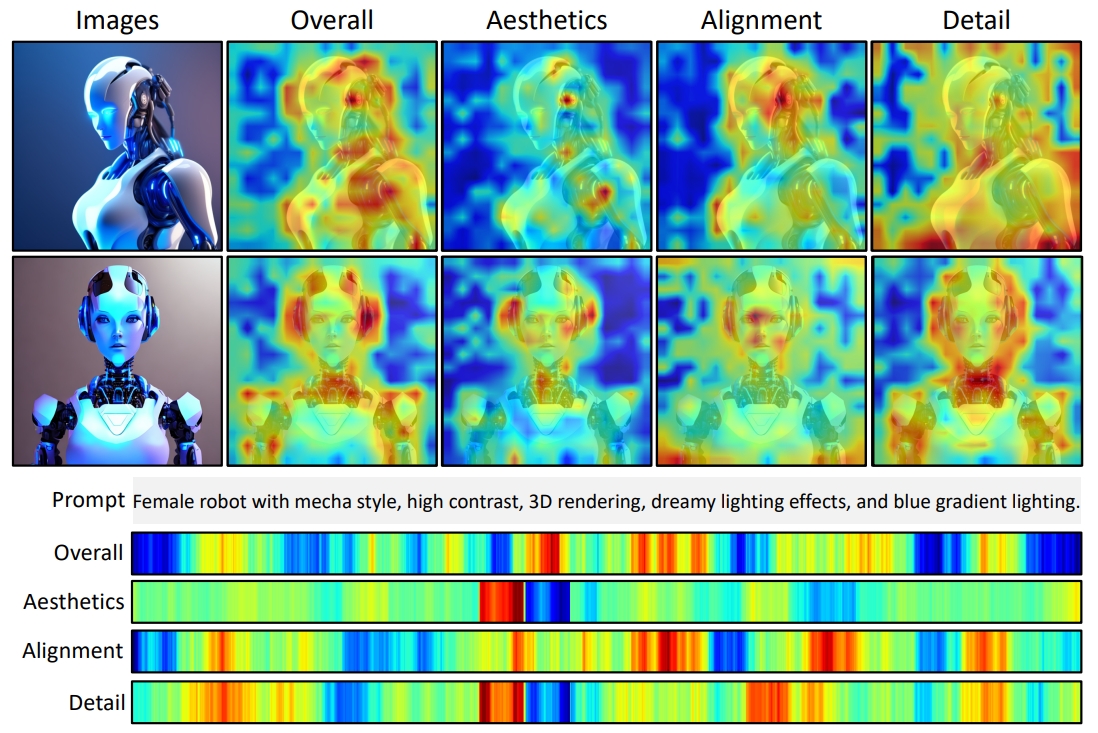
Multi-dimensional Human Preference (MHP) Dataset
To learn the multi-dimensional human preferences, we propose the Multi-dimensional Human Preference (MHP) dataset.
Compared to prior efforts, the MHP dataset offers significant enhancements in prompts collection, image generation, and preference annotation.
(1) For the prompt collection, based on the categories schema of Parti, we annotate the collected prompts into 7 category labels (e.g., characters, scenes, objects, animals, etc.).
For the underrepresented tail categories, we employ Large Language Models (LLMs) (e.g., GPT-4 \cite{GPT-4}) to generate additional prompts.
This process results in a balanced prompt collection across various categories, which is used for later image generation.
(2) For image generation, we not only utilize existing open-source Diffusion models and their variants, but also employ GANs and auto-regressive models to generate images.
Consequently, we generate a dataset of 607,541 images, which are further used to create 918,315 pairwise comparisons of images for preference annotation.
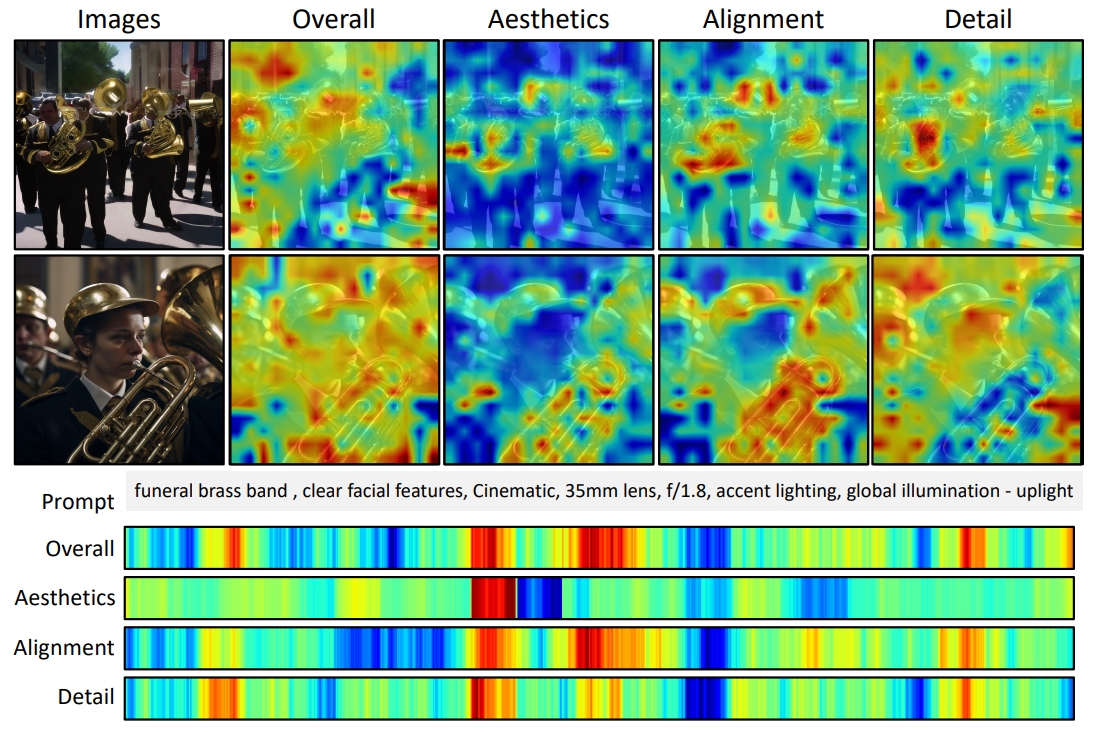
(3) For the annotation of human preferences, contrary to the single annotation of existing work, we consider a broader range of dimensions for human preferences and employ human annotators to label each image pair across four dimensions, including aesthetics, detail quality, semantic alignment, and overall score.